The problem
← All articlesWhy tests miss bugs
A green build means your tests passed. It does not mean your code is safe. Tests are written to verify what developers expected. They cannot verify what developers forgot, or what they removed.
The Green Build Fallacy
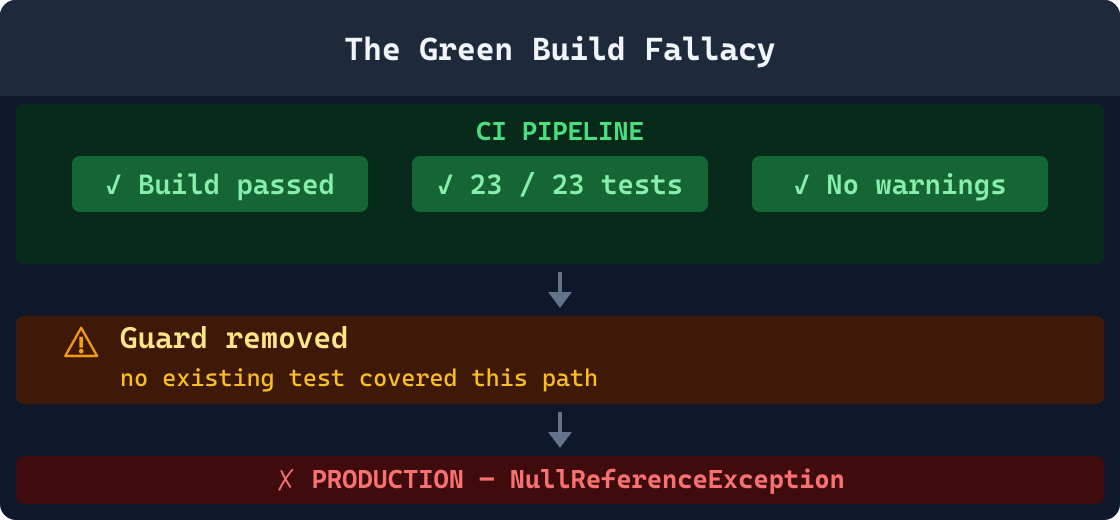
Most engineering teams treat a passing CI pipeline as a meaningful safety signal, and it is, to a point. A green build confirms that the tests you wrote still pass against the code you submitted. What it cannot confirm is that the code behaves correctly under all the conditions that matter in production: unexpected inputs, removed guards, changed contracts, and environmental differences that no test harness fully replicates.
Test suites are written by human developers at a specific point in time, against a specific understanding of the system. They encode what developers expected, not what the system needs to do. Every change to the codebase creates new behavioral surface area. Unless someone writes a new test at the exact moment of that change, the coverage gap grows silently, change by change, deploy by deploy.
The result is a growing divergence between "the tests pass" and "the system behaves correctly under all inputs." This gap is where production incidents live. It is not a failure of effort or care. It is the inherent structural limit of testing as a verification strategy when tests are written against a static snapshot of expectations.
Testing terminology: false negatives and false positives
A false negative is when a test passes despite a real defect existing: the suite says "all good" while the production system is broken. This is the core problem this article examines. A false positive (a test that fails when no real defect exists) is also harmful, but its primary damage is wasted developer time and eroded trust in the suite, not escaped bugs. The six categories below are all forms of false negatives: the test suite provides a false "no defects" signal while real behavioral regressions are already present in the codebase.
A 2002 study commissioned by the National Institute of Standards and Technology estimated that software defects cost the U.S. economy approximately $59.5 billion annually. The report identified inadequate testing infrastructure, not the absence of testing but the inability to detect defects introduced during development before they reach production, as a primary driver of that cost. [1] The Consortium for IT Software Quality (CISQ) updated this estimate in 2022, placing the cost of poor software quality in the U.S. at $2.41 trillion: driven largely by operational failures and the compounding cost of defects not caught during development. [6] Counter-evidence note: cost estimates vary significantly by methodology, scope, and era; treat both figures as order-of-magnitude indicators rather than precise measurements.
That cost is not evenly distributed across the development lifecycle. Defects that escape to production are consistently far more expensive to fix than defects caught at the source. Boehm and Basili found that detecting and correcting a defect in production costs between 10 and 100 times more than detecting it during development, depending on system type and the phase at which it is finally found. [4] Counter-evidence note: subsequent research in iterative development environments finds a narrower ratio, though the directional finding holds. The categories of bugs that tests miss most systematically are also the ones most likely to cause production incidents, because they involve changed behavior, not missing behavior, and changed behavior does not show up in tests that were written before the change was made.
7 categories of bugs that escape test suites
These are not exotic edge cases. They are the most common root causes behind production regressions in .NET codebases, and in every other typed, compiled language ecosystem. Each one represents a class of change that developers make routinely, that CI pipelines approve without hesitation, and that tests miss because they were written before the change existed.
Behavioral drift
A guard clause, fallback branch, or defensive early-return is quietly removed during a refactor. The developer's intent was to simplify the code, not to change its behavior, but the behavior did change. Existing tests never exercised that removed path because it was never added to the test suite in the first place. Every test still passes. The behavior of the system has silently shifted. These are among the hardest regressions to diagnose in production because the code looks correct: the method is shorter, the logic reads cleanly, and the CI pipeline is green. Static analysis of the diff is the only reliable way to surface this class of change before it ships.
Example
A null check before a database write is deleted during a cleanup refactor. No test in the suite covers the null path because all tests pass populated objects. The build is green. On the first null input in production, the database write throws an unhandled exception that corrupts a batch operation and requires a manual data repair.
Implicit contract changes
A public method's parameter type is widened from int to long, an enum value is renamed or removed, or a method that previously returned null begins throwing instead. The compiler is satisfied if all internal call sites were updated. But external consumers, including other services, serialization layers, stored procedures, mobile clients, and third-party integrations, relied on the old contract shape. That contract was never formally specified or tested from the consumer's perspective, so no test enforces it. The change compiles cleanly and deploys successfully. The implicit breakage surfaces at runtime in a different service, a different tier, or a different team's build.
Example
An API response field changes from a JSON string to a nested object during a backend refactor. The serialization layer compiles cleanly. All unit tests mock the response shape and still pass. Consumer services fail at runtime with deserialization exceptions on the first real API call after the deploy, requiring a hotfix and a coordinated rollback.
Missing null and edge-case guards
A developer adds a new code path that handles the expected happy-path case correctly and thoroughly. The edge cases (null inputs, empty collections, zero values, strings that exceed the expected length, timestamps in the past, and negative numbers in fields that expect positives) are not considered because they were not part of the original requirement or the bug report that prompted the change. Every test written for the new code uses clean, valid inputs and passes. Production surfaces the edge case within days, because real users do not read the assumptions behind the happy path, and real data is rarely as clean as test data.
Example
A refactored aggregation method gains a new LINQ operation but the developer forgets to handle an empty source collection. Every test provides a populated list. The first production request that submits an empty list causes an InvalidOperationException inside a LINQ operator, producing a 500 error in a previously stable endpoint and requiring an emergency deploy.
Config and environment side effects
A change reads a new environment variable, shifts a default timeout from 30 seconds to 5 seconds, introduces a new dependency on a service URL that must be injected, or hardcodes a value that was previously supplied by configuration. Unit tests mock or bypass the environment entirely, so they never touch the configuration surface. Integration tests may exercise the logic path but are run against a test configuration that does not match what production will see. The gap is in the setup, not the logic, and setup failures are invisible to assertion-based test suites because the tests never reach the point where the configuration difference matters.
Example
A developer adds a hardcoded database connection string for local development convenience and forgets to remove it before committing. All tests run against the test database using injected configuration and pass. Production ignores the injected environment variable for that connection and routes all traffic through the hardcoded value, writing to the wrong data store until the issue is detected hours later in monitoring.
Async and concurrency changes
An async void method is introduced where async Task is required, a .Result or .GetAwaiter().GetResult() call blocks a thread pool thread inside an async call chain, or shared mutable state is accessed from multiple concurrent tasks without synchronization. Unit tests run sequentially in a single-threaded environment where race conditions cannot materialize and thread pool exhaustion takes far longer to trigger than in any realistic test duration. The test suite gives no signal. The problem only becomes visible under real concurrency load in production, where it typically manifests intermittently, making it extremely difficult to reproduce, isolate, and diagnose without production observability tooling.
Example
A .Result call is introduced inside an async method that runs on the ASP.NET Core synchronization context during a service refactor. Single-threaded unit tests pass in milliseconds without any visible problem. Under production traffic, each concurrent request blocks a thread pool thread while waiting for the inner task, saturating the thread pool progressively and causing request timeouts that escalate into a full application deadlock requiring a service restart.
Dependency and schema drift
A NuGet package is updated and a previously stable API method changes its signature, adds a new required parameter, or alters its return type in a way the compiler does not catch at all internal call sites. A database migration removes a column that application code still references. A serialization attribute controlling JSON field naming is deleted from a DTO property. Tests are pinned to a specific package version or mock the dependency entirely, so they never encounter the changed interface. The real integration only surfaces when the updated code runs against the real external system, typically on the first deploy to a shared environment or to production.
Example
A widely-used NuGet package renames a configuration property in a minor version bump. All unit tests mock the package's interface and pass. The package updates without a compile error, and the build pipeline is green. The first request in production that exercises that configuration path throws a MissingMemberException, taking down the affected endpoint until the configuration is corrected and redeployed.
Flaky tests and the normalcy bias
A test that fails intermittently due to timing dependencies, ordering assumptions, or environmental variability is commonly disabled, skipped, or rationalized away. When teams become accustomed to a suite that sometimes fails for no clear reason, they lose the signal that CI is supposed to provide. Re-running a failure becomes routine. The normalcy bias compounds the problem: a module that has passed CI for eighteen months without a test covering a critical path is assumed to be safe, not merely untested. The absence of a failure is mistaken for the presence of correctness. When a real regression arrives, it is indistinguishable from the noise: and gets merged.
Example
A test that asserts on the order of items returned from a LINQ query fails on roughly one in ten runs because the underlying store does not guarantee sort order. The team adds it to the known-flaky list and re-runs on failure. A refactor later introduces a genuine ordering regression. The team sees the failure, re-runs, it passes on the retry (the new bug is also intermittent under the test data), and the change merges. The regression surfaces in production support tickets three weeks later.
Why code coverage is a misleading proxy for test quality
The most common organizational response to production bugs that escaped testing is to mandate higher code coverage thresholds. The intuition is reasonable: if a line was executed by at least one test, it was at least exercised. But the measure conflates execution with verification. Coverage tells you which lines ran. It says nothing about whether the assertions made during that run were correct, complete, or meaningful in any sense that connects to production correctness.
A test that calls a method and makes no assertions will contribute 100 percent line coverage to that method. A test that asserts on an incorrect expected value that happens to match the current (buggy) behavior will also show as covered and passing. A test written for the old behavior of a method will continue to cover that method after the behavior changes, as long as the new behavior still satisfies the old assertion. The coverage number stays stable. The correctness of the system does not.
Research finding: coverage does not predict fault detection
In a landmark empirical study published at ICSE 2014, Inozemtseva and Holmes analyzed over 31,000 test suites across multiple open-source Java projects and measured the correlation between line coverage, branch coverage, and actual fault detection effectiveness, meaning the ability to catch real, previously-discovered bugs. Their conclusion was unambiguous: "Coverage is not strongly correlated with test suite effectiveness." The Spearman rank correlation between line coverage and fault detection was weak across all studied projects. Branch coverage performed modestly better but remained an unreliable predictor of whether a test suite would catch real bugs. [2]
The Google Testing Blog reached a similar practical conclusion in 2020, noting that code coverage is useful as a lower bound: code that is never executed by any test definitely cannot be tested by those tests. But it is a poor upper bound. High coverage does not imply high confidence. It implies that lines were executed, which is a much weaker guarantee than "those lines behave correctly under all conditions that matter." [5]
This matters practically because coverage-driven development creates a false sense of safety that is particularly dangerous for the category of bugs tests miss most: removed behavior. When a guard clause is deleted from a method, the coverage of that method may actually increase: the method now has fewer branches, so the remaining branches are proportionally more covered by the existing tests. The coverage metric improves. The system degrades. The metric and the safety signal are moving in opposite directions.
The mutation testing gap: what uncaught mutations tell us
Mutation testing offers a more rigorous way to measure test suite quality than line or branch coverage. The technique introduces small, deliberate faults into the production codebase (a greater-than operator becomes greater-than-or-equal, an addition becomes subtraction, a boolean condition is negated, or a return value is changed) and then runs the full test suite against each mutated version. If the test suite fails with the mutation present, the mutation is "killed." If the tests still pass, the mutation "survived."
A high mutation survival rate reveals something important and actionable: large portions of the codebase can be arbitrarily altered, with exactly the kinds of mistakes that developers make in production, without any test noticing. Each survived mutation is a catalog entry of real production risk. Every off-by-one mutation that survives corresponds to a class of production bug that would also escape the test suite. Every survived negated condition is a real inversion bug waiting to be introduced.
Research by Just, Jalali, and Ernst using the Defects4J dataset (ISSTA 2014) found that mutation score is a substantially stronger predictor of real fault detection than statement coverage alone. Test suites with higher mutation scores, those that successfully kill more mutations, were measurably more effective at detecting actual previously-known bugs in the studied Java programs. Where line coverage showed weak predictive correlation, mutation score showed meaningful predictive correlation with fault detection ability. [3]
The practical obstacle to using mutation testing as a routine safety gate is its computational cost. A full mutation testing run on a large .NET codebase using a tool like Stryker.NET can take hours, which makes it impractical as a blocking check in a fast-feedback CI pipeline. Most teams run it infrequently if at all. The mutation score decays as new code is added without tests that cover the new behavioral surface, and the decay is invisible because the regular CI pipeline shows no degradation.
GauntletCI does not run mutation tests at commit time, but its structural rule engine is deliberately calibrated to the specific classes of change that mutation testing reveals are most commonly uncaught: removed guard clauses, inverted conditions, deleted fallback branches, and weakened boundary checks. These are the structural mutations that survive most test suites because no test was ever written to assert on the behavior that was removed or inverted.
A .NET example: the test that passes but misses the regression
The following illustrates behavioral drift in a realistic .NET service method. The original method has a guard clause that prevents invoice generation and email delivery for orders with no line items. During a routine "simplification" refactor, a developer removes the guard to reduce nesting and make the method more readable. The existing test suite, covering only the happy path with a valid, populated order, passes without modification. The behavioral regression ships to production.
// ORIGINAL -- GenerateInvoiceAsync before the refactor
public async Task<InvoiceResult> GenerateInvoiceAsync(Order order)
{
if (order.Items.Count == 0)
return InvoiceResult.Empty; // guard: skip empty orders
var invoice = await _invoiceService.CreateAsync(order);
await _emailService.SendAsync(order.CustomerEmail, invoice);
await _auditLog.RecordAsync("invoice_created", order.Id);
return InvoiceResult.From(invoice);
}
// CHANGED -- guard removed during a "simplification" refactor
public async Task<InvoiceResult> GenerateInvoiceAsync(Order order)
{
var invoice = await _invoiceService.CreateAsync(order);
await _emailService.SendAsync(order.CustomerEmail, invoice);
await _auditLog.RecordAsync("invoice_created", order.Id);
return InvoiceResult.From(invoice);
}
// THE TEST THAT STILL PASSES after the regression is introduced
[Fact]
public async Task GenerateInvoiceAsync_ValidOrder_CreatesInvoiceAndSendsEmail()
{
var order = new Order
{
Id = Guid.NewGuid(),
CustomerEmail = "customer@example.com",
Items = new List<OrderItem> { new OrderItem("Widget", 49.99m) }
};
var result = await _sut.GenerateInvoiceAsync(order);
Assert.Equal(InvoiceResultStatus.Created, result.Status);
_mockEmailService.Verify(
x => x.SendAsync(order.CustomerEmail, It.IsAny<Invoice>()),
Times.Once
);
}
// WHY IT PASSES: The test covers only the happy path with a populated order.
// The guard that was removed handled empty orders -- a path no existing test covered.
// After the refactor, empty orders now trigger invoice creation, email delivery,
// and audit logging. GauntletCI flags the removed guard clause (GCI0010).The test is not a bad test. It correctly verifies that a valid order with items produces a created invoice and triggers exactly one email delivery. It was written when the method was first implemented and captured the intended behavior at that time. The problem is that it was never extended to cover the empty-order path. So when the guard protecting that path was removed, nothing in the test suite detected the change.
This is the structural nature of the problem. The test suite was not wrong; it was incomplete with respect to the specific change that was made. And that incompleteness is not visible from the test results: all tests pass, coverage holds steady or increases, and the CI pipeline reports success. The only reliable way to detect this class of regression at commit time is to analyze the diff itself, recognizing that a guard clause was removed, and flag it for review before the change is pushed. See what is diff-based analysis for a deeper explanation of why analyzing the change, rather than the test results, is the necessary complement to test-based verification.
Property-based and fuzz testing: why they also miss structural drift
Property-based testing and fuzz testing represent a meaningful step forward from hand-written example-based unit tests. A property test generates hundreds or thousands of random inputs and verifies that a specified invariant holds across all of them: for example, that sorting a list always produces a result of the same length, that a discount calculation always returns a value between zero and the order total, or that serializing and then deserializing a record produces an identical record. A fuzzer generates millions of structurally unusual or malformed inputs to find crashes, assertion failures, or unexpected behavior.
These techniques are genuinely more powerful than single-example tests within their target domain. Property-based testing can discover bugs that no developer would think to test for, particularly in parsing, validation, type conversion, and pure computation logic. But they share a fundamental structural limitation with all input-driven testing: they can only test what they are written to test, and they can only detect failures that are observable through the input-output surface they are pointed at.
Structural drift, such as the removal of a guard clause, a changed default timeout value, or a deleted defensive fallback, is not detectable by varying inputs. It is detectable by analyzing what changed. A property test verifying "CalculateDiscount always returns a value between 0 and the order total" will not detect a regression that removes the guard preventing discount calculation on empty orders, as long as the new (incorrect) behavior still returns a number in that range for the generated inputs. The property holds. The behavior has fundamentally changed. The test passes.
Fuzz testing is similarly effective within its domain and similarly blind outside it. It excels at finding crashes, memory corruption, parser vulnerabilities, and type confusion. It does not detect that a method now sends an email where it previously returned early, or that a timeout was silently reduced from 30 seconds to 5 seconds, or that a serialization attribute governing JSON field naming was removed from a public DTO. These are behavioral changes caused by deleted lines, not new behaviors triggered by unusual inputs.
The practical takeaway is not that property-based or fuzz testing is insufficient; they are valuable and worth adopting alongside unit tests. The takeaway is that input-space testing and change-space analysis are complementary strategies that cover different classes of risk. Input-space testing catches what unusual inputs reveal. Diff-based structural analysis catches what the structure of the change itself reveals. Neither one makes the other redundant.
What tests catch well, and what they do not
Understanding where tests are genuinely strong makes it easier to understand where they structurally fail. Tests are most effective at catching bugs in isolated, pure logic with well-defined and stable input-output contracts: sorting algorithms, parsing functions, arithmetic operations, validation rules, state machine transitions. When you can precisely specify "given this input, expect this output," and the contract is stable across changes to unrelated code, tests provide strong and reliable regression protection. Every future regression against that specific behavior will be caught, indefinitely.
Tests become significantly less reliable across several specific structural categories:
Integration seams
When behavior depends on the interaction between two components, such as a service and its database, an HTTP client and a real downstream API, or a method and the precise expectations of all its callers, unit tests that mock the boundary can pass even when the real integration is broken. The mock encodes a specific assumption about how the boundary behaves. If the real contract changes and the mock is not updated to match, the test continues to pass against a fiction. The production integration fails on the first real request.
Temporal and environmental dependencies
Code that depends on the current time, environment variables, file system state, random number generators, or the availability of external services is hard to test deterministically. Tests that mock these dependencies confirm that the logic path executes correctly given a specific controlled mock value. They do not confirm that the environment interaction itself is correct, or that the behavior is correct across the full range of real values the dependency can produce in a live environment.
Removed behavior
This is the most systematic and structurally important gap. Tests assert on the presence of behavior: given input X, expect output Y. Standard testing frameworks have no general mechanism to assert on the absence of removed behavior. When a guard clause is deleted, no existing test fails unless that specific guard was explicitly tested in isolation. The deletion is structurally invisible to the test suite. Code coverage may even improve, since the method now has fewer branches and the remaining ones are proportionally more covered.
Cross-cutting side effects
A change that adds logging, modifies audit trail entries, triggers a background job, emits a metric, or sends a notification is invisible to tests that only assert on the return value of a method. Side effects that were previously not present, or that were previously prevented by a guard clause that was removed, can be introduced or exposed without any test detecting the addition or the unguarding.
There is also a structural bias built into the act of writing tests itself. Tests are written to confirm expectations, not to challenge them. A developer who implements a method and then writes its tests will naturally gravitate toward the inputs that make the method work : because those are the inputs the developer had in mind when writing the code. The edge cases that are not in the developer's mental model are not in the test suite either. This is not a failure of diligence; it is a property of how humans form and verify mental models. The same confirmation bias that makes a developer confident their code is correct makes the tests they write an imperfect instrument for proving that confidence wrong.
The practical implication is that tests should be understood as a necessary but not sufficient condition for production correctness. They are the right tool for verifying intended behavior against known inputs. They are not the right tool for detecting structural changes to the codebase that alter behavior in ways that were never explicitly specified in any test case. For that, you need analysis of the change itself.
This structural gap is parallel to the one in human code review. A reviewer reading a diff for correctness will verify that the changed lines look right. They will not necessarily notice that a critical line was removed, or that a guard clause protecting a side effect no longer appears. See why code review misses bugs for the parallel analysis of how human review exhibits the same systematic blind spots as automated test suites, and why automated structural analysis is needed alongside both.
Can TDD prevent these failures?
Test-Driven Development (TDD): writing the test before the code: is a meaningful partial mitigation for one specific subset of this problem. When a developer writes the failing test first, they are forced to define the expected behavior before implementing it. This reduces the likelihood of missing a test for newly added behavior, because the test is the specification for the addition.
TDD does not, however, prevent regressions caused by removed behavior. If a guard clause protecting a side effect was added in a prior iteration without a corresponding test, TDD provides no mechanism to detect when that guard is later deleted. The deletion produces no failing test because there was never a test written for that specific guard in the first place. The problem is not the order in which code and tests are written; it is the structural gap between what tests assert and what behavior was silently removed.
Diff-based structural analysis is therefore a complementary practice even for teams that practice TDD rigorously. TDD closes the "missing test for new additions" gap. Change-space analysis closes the "test never existed for what was removed" gap. Both gaps are real, and each tool is blind to the other's domain.
Bridging the gap: diff-based structural analysis
The complementary strategy to test-based verification is structural analysis of the change itself. Rather than running code against test inputs, this approach examines what was added and, critically, what was removed. Deleted guard clauses, removed null checks, inverted conditions, and async antipatterns all produce characteristic diff signatures identifiable before a change is committed, when correction costs nothing and developer context is freshest. Tests and structural diff analysis cover different risk surfaces, and neither makes the other redundant.
GauntletCI implements this strategy as a pre-commit rule engine. Each rule targets a specific class of structural change with a documented production failure mode: removed guard clauses, deleted null checks, inverted conditions, async void methods, missing CancellationToken propagation, and removed serialization attributes. Each rule exists because that class of structural change regularly produces production incidents that a fully green CI pipeline will not prevent.
Removed logic detection
Flags removed guard clauses, null checks, fallback branches, and early-return statements that have no corresponding updated test coverage. These are the structural mutations that survive most test suites because no test was written to assert on the behavior that was removed.
API contract analysis
Detects public method signature changes, removed serialization attributes, renamed enum values, deleted interface members, and parameter type widening that breaks downstream callers at runtime without any compile-time error at internal call sites.
Async and concurrency rules
Catches async void methods, blocking .Result and .GetAwaiter().GetResult() calls inside async chains, shared state mutations without synchronization, and missing CancellationToken propagation before they cause thread pool exhaustion or deadlocks in production.
References
- NIST. "The Economic Impacts of Inadequate Infrastructure for Software Testing." Planning Report 02-3. National Institute of Standards and Technology, 2002. https://www.nist.gov/system/files/documents/director/planning/report02-3.pdf
- Inozemtseva, L. and Holmes, R. "Coverage is Not Strongly Correlated with Test Suite Effectiveness." Proceedings of the 36th International Conference on Software Engineering (ICSE). ACM, 2014. https://dl.acm.org/doi/10.1145/2568225.2568271
- Just, R., Jalali, D., and Ernst, M.D. "Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs." Proceedings of the 2014 International Symposium on Software Testing and Analysis (ISSTA). ACM, 2014.
- Boehm, B. and Basili, V.R. "Software Defect Reduction Top 10 List." IEEE Computer, vol. 34, no. 1, pp. 135-137, January 2001.
- Google Testing Blog. "Code Coverage Best Practices." August 2020. https://testing.googleblog.com/2020/08/code-coverage-best-practices.html
- Consortium for IT Software Quality (CISQ). "The Cost of Poor Software Quality in the US: A 2022 Report." CISQ / Synopsys, 2022. https://www.it-cisq.org/the-cost-of-poor-software-quality-in-the-us-a-2022-report/
Eric Cogen -- Founder, GauntletCI
Twenty years in .NET production. Most of those years, the bugs that hurt me were not the ones tests caught. They were the assumptions I did not know I was making: a removed guard clause, a renamed method that still did the old thing, a catch {} that turned a page into a silent dashboard lie. GauntletCI is the checklist I wish I had run before every commit. It runs the rules I learned the hard way, so you do not have to.