Concept
← All articlesWhat is diff-based analysis?
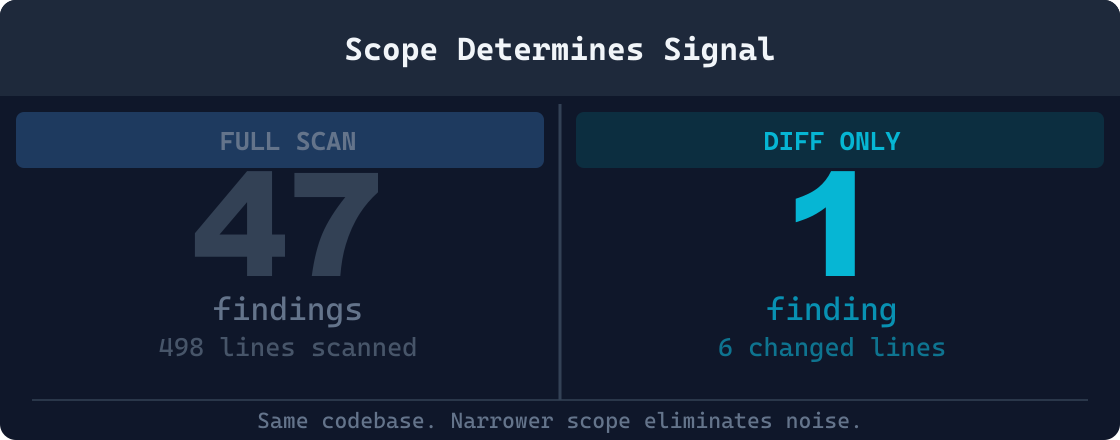
Diff-based analysis examines only the lines you changed, not the entire codebase. It answers the question: "What risk did this change introduce?" rather than "What risk exists in the whole project?"
This distinction is not cosmetic. The scope of what a tool analyzes determines who uses it, how often, and whether its findings get acted on. Decades of research on static analysis adoption tell a consistent story: developers abandon tools that cry wolf, and they keep using tools that surface only what matters right now. Diff-based analysis is the structural answer to that adoption problem.
How diff-based analysis works
When you stage changes with git add, Git records a diff: the exact lines added, modified, and removed. A diff-based analysis engine operates on this diff as its sole input. It does not load, parse, or scan any file that was not touched by the current changeset. Every finding the tool produces is directly traceable to a line in the current diff.
The engine reads each changed hunk, identifies the structural role of the modified lines (is this a guard clause? a public method signature? a serialization attribute? a dependency injection registration?), and evaluates a set of targeted rules against those structural properties. Critically, each rule fires on the delta (the change itself), not on the surrounding stable code that has been in production for months.
The example below shows a single-line deletion. A guard clause that validated the method input has been removed: a category of change that code review consistently misses for structural reasons. A full-codebase scanner may or may not surface this depending on whether it has a rule for missing input validation. A diff-based scanner surfaces it immediately because it can see the deletion (the removed line) and knows what was there before.
staged diff (simplified)
@@ -42,7 +42,6 @@
public async Task<User> GetUserAsync(int id)
{
- if (id <= 0) throw new ArgumentException(nameof(id));
return await _repo.FindAsync(id);
}
GCI0001: Removed guard clause at line 44 -- ArgumentException on invalid input is no longer thrown.
The false positive problem: why developers abandon full-codebase scanners
A 2013 study published at the International Conference on Software Engineering examined why developers do not use static analysis tools even when those tools are available [1]. The top-ranked reason was false positives, ahead of performance, installation friction, and IDE integration gaps. Developers who encounter a tool that fires on pre-existing, known-benign patterns quickly learn to ignore it. Once a tool trains developers to ignore it, it has negative utility: it adds cognitive load with no corresponding benefit. Studies examining different tool types and organizational contexts identify performance overhead and integration friction as additional significant barriers, though false positives rank consistently near the top.
Google observed the same dynamic at scale. In their 2018 Communications of the ACM paper on lessons from building static analysis tools across the full Google codebase, the authors describe how they deliberately ship only checks where confidence is very high [2]. Their internal tools were not rejected because they were slow or hard to install. They were rejected when the signal-to-noise ratio dropped below the threshold where a developer found it worth reading findings at all. The team eventually required that any new check demonstrate a low false positive rate on existing code before it could be turned on.
Full-codebase scanning amplifies the false positive problem structurally. Every scan re-reports the same issues that were in the codebase before the developer touched anything. Technical debt accumulated years ago floods the results. A developer who changed two lines in one file sees hundreds of findings across the project, none of which are things they introduced and most of which their team has already decided to defer.The tool is technically correct, but it is not useful for the task the developer is actually doing.
Beller et al. evaluated static analysis adoption in open source projects and found that even teams that had integrated static analysis into their CI pipelines frequently disabled or silenced large categories of warnings over time [3]. The pattern is predictable enough to have a name: the tool abandonment cycle. A team adopts a scanner, the finding count grows, developers start suppressing rules, and eventually the tool runs silently in CI producing output nobody reads. Each step is rational in isolation; the cumulative outcome is a tool that provides negative value.Teams that maintain sustained adoption typically roll out rule sets incrementally rather than enabling all checks at once; adoption patterns vary significantly by team size and codebase maturity.
Diff-based analysis sidesteps this failure mode by construction. Because it only analyzes what changed, the maximum finding count for any given commit is bounded by the size of the diff. A two-line change produces at most a small number of findings, and every one of those findings is about the two lines the developer just wrote. There is no accumulated backlog of pre-existing issues competing for attention.
Signal-to-noise ratio: the metric that determines whether developers trust a tool
The practical measure of a static analysis tool is not its recall rate on a test suite of known bugs. It is whether a developer, in the middle of shipping a feature, stops what they are doing and acts on a finding. That behavior requires trust, and trust requires a track record of findings that were worth acting on.
Signal-to-noise ratio (SNR) is the fraction of tool findings that represent genuine, actionable risk versus total findings. A tool with high recall but low SNR produces many true positives alongside many false positives. Because developers cannot cheaply distinguish which is which (doing so would require the analysis they were hoping the tool would do for them), they treat all findings as suspect and eventually treat all findings as ignorable.
Ayewah et al. studied false positive rates in FindBugs (now SpotBugs) deployments and found that false positive rates varied enormously by rule category [4]. Some rule categories were nearly always correct. Others fired on benign patterns more often than not. The practical lesson was not to tune the rules in isolation but to restrict which rules run in which contexts: a finding that is 40% likely to be a false positive in a full-codebase scan may be 90% likely to be a true positive when scoped to lines that were just modified. More recent tooling has reduced false positive rates in some categories; the core finding that context governs precision remains consistent.
Rules scoped to the diff context fire only when a problem is introduced by the current change. A rule about removing a guard clause fires when a guard clause is removed in the current diff; it does not fire when a guard clause is absent from a stable file that has been in production for two years and whose absence was a deliberate design decision. The same rule logic, applied at different scope, produces radically different SNR. Scoping rules to the delta rather than the full file is the primary mechanism by which diff-based analysis achieves a higher SNR than equivalent rules running over a full codebase.
High SNR has a compounding benefit. When a developer acts on every finding they receive, the tool becomes part of their normal workflow. They do not develop the habit of dismissing findings without reading them. This means that when a genuinely critical finding appears (a removed authentication check, a hardcoded secret, abroken serialization contract) it gets the same attention every other finding receives, rather than being lost in a backlog of noise.
How GauntletCI's diff parser works technically
Understanding how a diff-based engine works requires understanding the structure of a unified diff, which is what git diff and git diff --cached produce. A unified diff is composed of file headers, hunk headers, and hunk bodies. The hunk header is the @@ line. The hunk body contains context lines (prefixed with a space), added lines (prefixed with +), and removed lines (prefixed with -).
Here is a representative unified diff with multiple change types:
raw unified diff output -- git diff --cached
diff --git a/src/UserService.cs b/src/UserService.cs
index 3a9f1d2..b7c840e 100644
--- a/src/UserService.cs
+++ b/src/UserService.cs
@@ -38,12 +38,10 @@ public class UserService
/// <summary>Retrieves a user by identifier.</summary>
public async Task<User> GetUserAsync(int id)
{
- if (id <= 0)
- throw new ArgumentOutOfRangeException(nameof(id));
var cached = _cache.Get(id);
if (cached != null) return cached;
+ // TODO: restore validation
return await _repo.FindAsync(id);
}
GauntletCI processes this input in three passes. In the first pass it splits the raw text into file sections separated by the diff --git header, extracting the old path and new path for each changed file. In the second pass it splits each file section into hunks at each @@ boundary. In the third pass it classifies each line within a hunk as a context line, an added line, or a removed line, and records the original and new line numbers using the hunk header coordinates.
The @@ header encodes four numbers: the starting line in the old file, the count of lines shown from the old file, the starting line in the new file, and the count of lines shown in the new file. The format is @@ -old_start,old_count +new_start,new_count @@. In the example above, -38,12 +38,10 means the hunk shows 12 lines from the old file starting at line 38, and 10 lines from the new file starting at line 38. The two-line reduction is the deleted guard clause: two removed lines, no replaced lines.
After parsing, each rule receives a structured representation: a list of changed hunks, each containing typed line objects with their content, their old and new line numbers, and their change type (added, removed, or context). Rules do not do any text parsing of their own. They pattern-match against the structured representation. A rule that looks for removed guard clauses queries: in any hunk, is there a sequence of removed lines that matches the pattern of a guard clause (a conditional followed by a throw or early return) at the top of a method body? If yes, fire. If no, move on. The rule never reads the surrounding file.
Context lines are included in the hunk representation but are never the subject of a finding. Their purpose is to give rules enough surrounding code to make a structural judgment. A removed line that looks like a throw statement is more clearly a guard clause if the context lines confirm it was inside an if block near the top of a method. Context lines provide that framing without expanding the scope of what the engine analyzes to the full file. Typically three lines of context are provided on each side of a changed block, which is the default for unified diffs and is sufficient for most structural pattern matching.
Integration points: where diff-based analysis fits in the development workflow
Analysis tools can run at several points in the development lifecycle. Each integration point has different characteristics for feedback latency, developer context, and cost of remediation. Diff-based analysis is well-suited to the earliest integration points precisely because it operates on diffs; a diff is always available as long as there are staged or unstaged changes.
Pre-commit
Pre-commit is the earliest integration point. The developer has just finished writing code and is about to record a snapshot. The diff is the exact set of changes they intend to commit. Running analysis here means the developer receives findings before the change becomes part of repository history. Fixing a finding is a file edit: no branch, no PR, no review cycle required. The cost is measured in seconds.
Pre-commit hooks also run locally, which means no network round trip and no CI queue wait. GauntletCI is designed to complete analysis in under one second on a typical diff, making it fast enough to run on every commit without disrupting developer flow. The hook receives the staged diff directly from Git and returns structured findings before the commit object is created.
CI pipeline (pre-merge)
Running diff-based analysis in CI, against the PR diff, is the second natural integration point. At this stage the developer has already committed and pushed. The diff is still well-defined (the branch diff against main), but the cost of fixing a finding is higher: a new commit, a push, and a re-run of CI. The developer may have context-switched to other work. Feedback latency is minutes to tens of minutes depending on queue depth.
CI is a good fallback for teams that cannot or do not enforce pre-commit hooks uniformly. It also serves as a hard gate when team policy requires all findings to be clear before merge, regardless of whether the developer ran the hook locally. Running the same GauntletCI binary in CI that runs locally ensures consistent findings across both environments.
IDE and editor integration
Some teams run analysis on save or on file change within the editor. This is the fastest feedback loop possible: sub-second latency, with findings surfaced inline while the code is still on screen. GauntletCI can be invoked with a diff piped from the editor change buffer, making real-time IDE integration achievable. The tradeoff is that partial changes (code that is syntactically incomplete or not yet compiling) can produce noisy results. Many teams use IDE integration for advisory findings and pre-commit integration for hard gates that block the commit.
Pre-commit
Seconds to fix
CI (pre-merge)
Minutes to fix
Post-deploy
Hours to days
Cost of fixing the same defect at different stages of the development lifecycle.
How it compares to full-codebase scanning
The table below captures the practical differences between a full-codebase scanner running on a schedule or in CI and a diff-based engine running at pre-commit. These are complementary approaches, not competing ones; understanding the tradeoffs helps teams decide when to rely on each and where to invest in tuning.
| Dimension | Full-codebase scan | Diff-based (GauntletCI) |
|---|---|---|
| Scope | Every file in the project | Only changed lines |
| Run time | Minutes to hours on large codebases | Under one second |
| When it runs | Scheduled or CI pipeline | Pre-commit, on every save |
| Signal type | Existing issues in the full codebase | Risk introduced by this change |
| Noise | High: existing issues reappear every run | Low: only new delta is analyzed |
| Actionability | Requires triage across the full backlog | Directly actionable: one change, one finding |
| False positive rate | Higher: rules fire on any matching pattern | Lower: rules scoped to changed lines only |
| Developer interrupt cost | Findings arrive minutes later in CI or on a schedule | Findings arrive before the commit is recorded |
| Trust trajectory | Declines as finding count grows and backlog accumulates | Stable: findings are always about current work |
| CI feedback latency | Full scan blocks CI for minutes to hours | Pre-commit prevents the issue from reaching CI at all |
The economics of early detection
The cost of a defect is not fixed. It scales with the distance between when the defect was introduced and when it is detected. A guard clause removed in a pre-commit change is a two-second fix: restore the line, stage it again, re-run the hook. The same guard clause removal found in code review requires a PR comment thread, a context switch back to the code, a new commit, a push, and a re-review pass. Found after deploy, it is a production incident with a rollback, an on-call page, and a postmortem.
This is not a theoretical claim. Research on defect cost amplification going back to the 1970s consistently finds that the cost ratio between detecting a defect early in development versus in production can be 10:1 to 100:1 or higher depending on the severity and the system involved. Pre-commit detection is not quite design time, but it is the closest practical analog in a modern commit-based workflow. The developer still has the change in working memory, the editor is open, and no other person time has been spent yet.
Diff-based analysis is uniquely positioned to deliver pre-commit feedback because its input is the diff: exactly what the pre-commit hook has available. There is no need to check out the full repository, run a build, or wait for a CI environment. The staged diff is available immediately, and the analysis completes before the commit is finalized.
Code review, even when thorough, is a probabilistic gate. Reviewers miss things, especially behavioral regressions introduced by deletions rather than additions. See why code review misses bugs for a detailed treatment of the systematic blind spots in human review. Diff-based analysis fills those gaps deterministically: it will always apply the same rules to the same diff and produce the same findings, regardless of reviewer fatigue, diff size, or social pressure to approve quickly.
For teams concerned specifically about API contract breaks, serialization regressions, and removed overloads, see detecting breaking changes before merge. That article covers how diff-based rules identify breaking changes in public interfaces, REST contracts, and binary-compatibility-sensitive types, categories of change that are almost invisible in code review but trivially detectable in a structured diff.
Diff-based analysis is complementary, not competitive
Full-codebase scanning tools like SonarQube, Semgrep, and CodeQL serve a different purpose: finding existing issues across the full codebase on a schedule. A diff-based pre-commit tool does not replace them; it adds a pre-commit gate that flags the risk introduced by the current change before that risk becomes part of the baseline the scanner has to manage. Running both approaches provides defense in depth: new risk is caught at the earliest possible moment, and existing risk is tracked over time with a dedicated tool suited to that task.
For teams migrating to a scanner from a codebase with no prior analysis, diff-based tooling also offers a practical migration path. Rather than being confronted with thousands of pre-existing findings on day one, the team can freeze the existing baseline and use diff-based analysis to ensure no new issues are introduced going forward. Technical debt is addressed incrementally without blocking current work.
Related topics
Why code review misses bugs
The systematic blind spots in human review that diff-based analysis fills deterministically, including deleted validations, implicit contracts, and concurrency anti-patterns.
Detect breaking changes before merge
How GauntletCI uses diff rules to surface API contract violations, removed overloads, and serialization breaks before they reach main.
References
- [1]B. Johnson, Y. Song, E. Murphy-Hill, and R. Bowdidge, "Why Don't Software Developers Use Static Analysis Tools to Find Bugs?" in Proc. ICSE 2013, pp. 672-681. https://dl.acm.org/doi/10.1109/ICSE.2013.6606613
- [2]C. Sadowski, J. van Gogh, C. Jaspan, E. Soderberg, and C. Winter, "Lessons from Building Static Analysis Tools at Google," Commun. ACM, vol. 61, no. 4, pp. 58-66, 2018. https://dl.acm.org/doi/10.1145/3188720
- [3]M. Beller, R. Bholanath, S. McIntosh, and A. Zaidman, "Analyzing the State of Static Analysis: A Large-Scale Evaluation in Open Source Software," in Proc. SANER 2016. https://ieeexplore.ieee.org/document/7476770
- [4]N. Ayewah, W. Pugh, J. D. Morgenthaler, J. Penix, and Y. Zhou, "Using Static Analysis to Find Bugs," IEEE Software, vol. 25, no. 5, pp. 22-29, 2008.
Eric Cogen -- Founder, GauntletCI
Twenty years in .NET production. Most of those years, the bugs that hurt me were not the ones tests caught. They were the assumptions I did not know I was making: a removed guard clause, a renamed method that still did the old thing, a catch {} that turned a page into a silent dashboard lie. GauntletCI is the checklist I wish I had run before every commit. It runs the rules I learned the hard way, so you do not have to.